All You Ever Wanted to Know About Java Exceptions
Exception handling is a mechanism used to handle disruptive, abnormal conditions to the control flow of our programs. The concept can be traced back to the origins of Lisp and is used in many different programming languages today.
If a program reaches such an abnormal condition, the Java runtime tries to find an appropriate exception handler by going through the call stack. This behavior is called “exception propagation”, and behaves differently regarding the type of exception.
Table of Contents
Different Kinds of Exceptions
Exceptions can be categorized into 2 categories that differ in coding requirements and behavior: Checked and Unchecked Exceptions.
Checked Exceptions
Checked exceptions are anticipated, and recoverable events outside of the normal control flow.
A good example is the FileNotFoundException, or MalformedURLException.
Because they are supposed to be anticipated, the compiler makes sure we declare them on our method signatures, and enforces either handling or propagating them further up the call stack. This is called the “catch or specify requirement”.
Checked Exceptions must be propagated explicitly using the throws keyword.
All exceptions are checked exceptions, except subclasses of RuntimeException or Error.
Unchecked Exceptions
Unchecked exceptions are not anticipated and are often supposed to be unrecoverable. They are not required to conform to the “catch or specify requirement”.
They will be automatically propagated up the call stack until an appropriate exception handler is found. Or, if none is found, the runtime terminates.
All exceptions subclassing either RuntimeException or Error are unchecked.
RuntimeException
As the name implies, these exceptions are happening at runtime, often due to programming problems and bugs.
Examples we all know are the classics like NullPointerException, or ArithmeticException.
If our program crashes thanks to a NullPointerException, it’s an indicator that we didn’t do enough validation, or forgot to initialize a value.
If a method returns such an exception, it might be anticipated, like List#get(int index).
But as unchecked exceptions, they don’t have to be documented in any way.
Errors
Errors are unanticipated and unrecoverable events, usually thrown by the runtime itself.
For example, if the runtime runs out of available memory, an OutOfMemoryError is thrown.
Or an endless recursive call could create a StackOverflowError.
Faulty hardware might lead to an IOError.
These are all grave errors with almost no possibility to recover gracefully, except for printing the current stack trace.
All subclasses of Error fall into this category, and by convention are named ...Error instead of ...Exception.
Throwable and its Subtypes
Handling Exceptions
The basic concept of handling exception comprises 3 (+1) keywords initiating code blocks interacting with each other:
try {
// open a file
// read file
// do the work
}
catch(FileNotFoundException e) {
// handle missing file
}
catch (IOException e) {
// handle any other IO related exception
}
finally {
// cleanup
// log file access for audit log
}The order of the blocks is essential.
All exception handling starts with a try block, followed by zero or more catch blocks, and ends with a single, but optional, finally block.
try
A try block creates the scope we want to handle exceptions for.
It can’t exist without at least one catch or a single finally block.
catch
A catch block is known as an exception handler.
The exception type handled must be specified by declaring a variable.
Multiple catch blocks with different exception types are possible.
But they must be ordered according to their (possible) relationships.
This means the first catch block could catch a FileNotFoundException, a subtype of IOException.
The next catch block can catch IOException, and all it subtypes directly.
If ordered in reverse, catching IOException before FileNotFoundException, the compiler will complain.
The first block would catch FileNotFoundException because it’s inherited from IOException`, making the declaration of the second block invalid.
Multi-catch
Instead of creating a catch for every single exception type we want (or need) to handle, we can combine them, if their handling logic can be consolidated:
try {
...
}
catch (FileNotFound | UnsupportedEncodingException e) {
...
}The combined variable will be either exception, but will have the type of the most common ancestor:
FileNotFoundException|UnsupportedEncodingException
will become anIOExceptionFileNotFoundException|ClassNotFoundExceptionwill become anException.
Multi- and single-type catch blocks can be used in tandem.
But the rules about ordering from most to least specific still apply. And any type can only be caught once.
finally
The finally block is an optional code block that is guaranteed to execute after the try scope is left, either by successfully completing the try block, or leaving a catch block.
It’s the right place for any required cleanup, regardless of the success of the try block.
Dealing with resources can be simplified by using try-with-resource feature introduced in Java 1.7.
The guarantee to execute might not be fulfilled in case of severe runtime issues, like OutOfMemoryError or StackOverflowError, etc.
try-with-resource
Cleaning up resources was usually done in thefinally block, due to the guarantee to execute in any case:
FileReader reader = null;
try {
reader = new FileReader("awesome-file.txt");
int content = 0;
while (content != -1) {
content = reader.read();
...
}
}
catch (IOException e) {
// handle any exceptions
}
finally {
if (reader == null) {
return;
}
try {
reader.close();
} catch (IOException e) {
// handle any exception occured on close
}
}With Java 1.7 an addition to the try keyword was introduced: try-with-resources:
try (FileReader reader = new FileReader("awesome-file.txt")) {
int content = 0;
while (content != -1) {
content = reader.read();
...
}
}
catch (IOException e) {
// handle any exceptions
}Objects implementing AutoCloseable can be created right after the try keyword, surrounded by parenthesis. We’re not restricted to a single object, multiple object creation can be separated by a semi-colon(;):
try (Socket socket = new Socket();
InputStream input = new DataInputStream(socket.getInputStream());
OutputStream output = new DataOutputStream(socket.getOutputStream())) {
...
}Any AutoCloseable will be closed, after the scope of try will be left, either successfully, or via a catch block. The closing order will be reversed to the creation order.
The key difference from handling resources ourselves in a finally block is the possibility of additional exceptions during any close-operation.
In the example above, every object might throw an exception on closing.
The first occurred exception will be handled by the appropriate catch.
Additional exceptions will be available via the exception’s getSupressed()() method.
This way, we don’t need another try/catch for closing.
But it means that an exception during the closing operation might end up being handled by a catch block that was designed to handle an exception for non-closed-related code.
Dealing with a closeable resource is much more straightforward and less code.
But we have to deal with suppressed exceptions and can’t add additional code around the close-operation.
And using try-with-resources doesn’t prevent us from supplying a finally block, though, for any additional cleanup/logging we might need.
Exception Flow
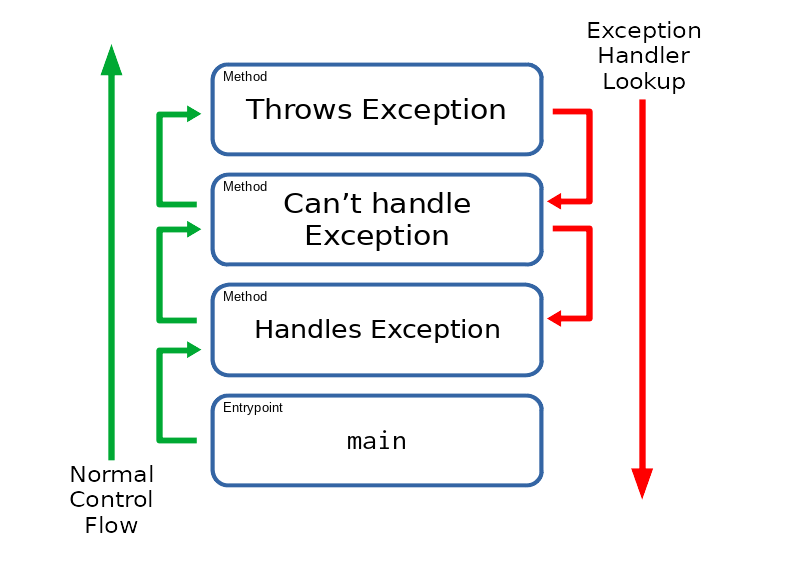
Throwing Exceptions
Now that we know how to handle exceptions, it’s time to learn about throwing them.
throw
Java uses the keyword throw to leave the normal control flow and propagate an exception to an appropriate handler:
public void logMessage(String message) {
if (message == null) {
throw new NullPointerException("'message' must not be null'");
}
if (message.isEmpty()) {
throw new IllegalArgumentException("'message' must not be empty");
}
// ...
}The keyword must be followed by an instance of a Throwable or subclass.
It doesn’t have to be new, we can even re-throw an exception in a catch block.
Checked exceptions must still oblige the “catch or specify requirement”, so we need either directly catch the exception (doesn’t make sense), or use the next keyword, throws, instead.
throws
With the help of the keyword throws, we can specify any thrown checked exceptions directly on a method signature.
This makes the compiler happy by satisfying the “catch or specify requirement”.
The exception doesn’t have to be thrown directly in the scope of the method. Any called code might throw the exception, and our method will propagate the exception further up the call stack:
interface MyInterface {
void doWork() throws IOException;
}
class MyClass {
public void moreWork() throws FileNotFoundException {
...
}
}Unchecked exceptions can be specified, too. But there are no compile-time advantages to doing so, no one will force us to catch it.
By implementing an interface or subclassing a type, we can modify the specified exception types.
Modifying types thrown
Just because an interface or a class has specified a specific exception type, doesn’t mean we have to obey it in an implementation or subclass.
Sub-types can use the original throws declaration or modify it:
- Throw a subclass of the original exception:
throws Exception->throws IOException - Remove the
throwsdeclaration:throws Exception-> n/a
Java itself used this feature to implement AutoCloseable, by making it the parent class of Closeable:
public interface AutoCloseable {
void close() throws Exception;
}
public interface Closeable extends AutoCloseable {
void close() throws IOException;
}Now try-with-resource works for every previously existing type that implements Closeable, without changing any of our code.
Although it wouldn’t be strictly necessary to change any implementation, because IOException is a subclass of Exception, it would have changed the method signature of code that’s not maintained by Java.
This feature also can lead to weird behavior, regarding which type we use:
interface WithException {
void doWork() throws IOException;
}
class WithoutException implements WithException {
// We omit the exception in the implementation
@Override
public void doWork() {
...
}
}
// Won't compile without try-catch
WithException with = new WithoutException();
// Compiler won't complain
WithoutException without = new WithoutException();Chained Exceptions
Added in Java 1.4, chained exceptions are a mechanism to respond to an exception with another exception.
The original Throwable is embedded and available via getCause().
It can be set (publicly) in 2 different ways:
The biggest advantage of chained exceptions is the possibility to elevate the initially thrown exception into the same layer of abstraction as the surrounding scope. We can be more specific with the new exception, providing essential information needed for sensible logging and debugging purposes.
Creating Custom Exceptions
We’re not restricted to the exceptions provided by the JDK, we can easily create our own.
So why should we?
The most general cases are covered by the JDK. But there are scenarios where we need more fine-grained control or more information about the circumstances that lead to an exception.
We can throw custom exceptions directly, or we can re-throw them as a chained exception.
Providing a Benefit
A custom exception should always provide a benefit, not just replicating an existing exception and its purpose with a new type. By adding additional fields, we can supply more information, allowing special handling for a particular case. Usually, an exception tells us what happened, but not much about why it happened. With a custom exception, it can:
public class ValidationException extends Exception {
private final String field;
public ValidationException(String field,
String message,
Throwable cause) {
super(message, cause);
this.field = field;
}
public String getField() {
return this.field;
}
}With this ValidationException, we can handle validation problems besides more general exceptions and also get the field name. Another improvement would by providing the type of validation failed, or any other information we might need to handle the exception efficiently.
Business Logic Exceptions
So far, we’ve used exceptions to describe and handle disruptive events in the normal control flow. But we can use exceptions to reflect disruptions in our business logic, too:
public class CustomerRegistrationException extends Exception {
private final String email;
public CustomerRegistrationException(String email) {
super("Registration failed for " + email);
this.email = email;
}
public String getEmail() {
return this.email;
}
}It seems alluring to use exceptions for more fine-grained control over business logic problems. But be aware of the performance implications!
Creating exceptions isn’t free, and overusing them for the wrong reasons will have an impact.
Performance Implications
Everything we do has performance implications, nothing’s for free. But some things can be cheap, so we need to know which features won’t affect the performance too much, and which are.
Java’s exception can be both.
Some parts are almost free, others are immensely expensive, depending on how we use them.
Handling Exceptions
A try-catch block is almost free.
The compiler adds an exception table with the corresponding range to the method and the target position for handling it:
public float divide(float divident, float divisor) {
try {
return divident / divisor
}
catch (ArithmeticException e) {
System.out.println("Division error");
}
return 0.0f;
}This simple method translates following byte-code (shortened for readability):
public float divide(float, float);
Code:
0: fload_1
1: fload_2
2: fdiv
3: freturn
4: astore_3
5: getstatic #3 // Field System.out:LPrintStream;
8: ldc #4 // String Division Error
10: invokevirtual #5 // Method PrintStream.println:(LString;)V
13: fconst_0
14: freturn
Exception table:
from to target type
0 3 4 Class java/lang/ArithmeticExceptionWithout the try-catch we got fewer opcodes in total:
public float divide(float, float);
Code:
0: fload_1
1: fload_2
2: fdiv
3: freturnIf we ignore the additional opcodes of the actual exception handling in the first example (4–13), the try-catch doesn’t need a single additional opcode at runtime.
If we wouldn’t return in the try, only a goto would have been added.
We got more bytecode, but under non-error circumstances, we still have no impact.
And the added value of possible exception handling.
So there’s no need to neglect exception handling in fear of performance impact.
Throwing Exceptions
We don’t have to worry about the performance impact of throwing an exception.
It’s just a single opcode: athrow.
The bigger problem is that we need an instance of an exception type to throw, and its creation can be very costly.
Usually, the creation of objects is easily determinable and constant in complexity. Exceptions, on the other hand, are not, due to containing a stack trace.
At creation time, an exception will gather all stack frames in the current call stack, so we can access it with Throwable#getStackTrace().
The deeper the current call stack is, the costlier its gathering will be.
Even if we actually don’t care about the stack trace and might only pop one or two stack frames.
Throwing repeatedly in short succession is most likely a bigger problem. It can become so costly for the runtime, that it might omit the stack trace if too many exceptions are created repeatedly.
But if we really want to make sure that the stack trace is always included, regardless of its cost, we can use the JVM option -XX:-OmitStackTraceInFastThrow.
Cheaper Exceptions
There are several options for reducing the cost of exceptions:
The
Throwable(String, Throwable, boolean boolean)constructorUsing
staticexceptions
The type Throwable, which is a supertype to all exceptions and errors, provides multiple constructors.
One of it allows more precise control of how an instance is created.
It’s protected, so it’s only available to our own custom types:
protected Throwable(String message,
Throwable cause,
boolean enableSuppression,
boolean writableStackTrace) {
if (writableStackTrace) {
fillInStackTrace();
}
else {
stackTrace = null;
}
detailMessage = message;
this.cause = cause;
if (!enableSuppression) {
suppressedExceptions = null;
}
}By using this particular constructor, we can build cheaper exception instances.
All other constructors will always call Throwable#fillInStackTrace().
This can be really useful when the signal that an exception occurs is more important than the whole reason why.
My previous business logic exception example could be a good fit. We don’t need a stack trace if a customer registration fails due to validation issues.
Another option is creating a static instance of the desired exception type and throwing it instead of creating a new one.
Just because we don’t really create a new instance, we don’t need to forfeit the advantages of having a stack trace altogether.
By calling Throwable#fillInStackTrace() manually, we can have an on-demand stack trace.
Dos & Don’ts
Always throw the most specific exception type possible.
Be As Specific As Possible
The catcher can decide to only handle a broader type, but can’t change the specificity of the thrown type. So if we can provide the handler with more differentiable options, we should.
Let’s check out the type hierarchy of ClosedByInterruptException:
java.lang.Throwable
java.lang.Exception
java.io.IOException
java.nio.channels.ClosedChannelException
java.nio.channels.AsynchronousCloseException
java.nio.channels.ClosedByInterruptExceptionThese are distinct exceptions for different kinds of disruptions of the normal control flow.
And each one might be handled differently.
If the handler doesn’t care about the finer details, they can use catch (IOException e)instead of a more specific type.
Document Exceptions with Javadoc
All exceptions thrown by a method should be documented with Javadoc’s @throw <type> <description>.
You might argue that unchecked exceptions are not part of the method contract, and therefore shouldn’t be documented. That’s a valid viewpoint, they represent what happens when the contract gets violated, and are most likely unrecoverable.
But in my opinion, every shred of extra information to fulfill such a contract might help.
If a method doesn’t allow null for an argument, why not communicate it clearly by documenting a possible NullPointerException?
When deciding against documenting such an exception, we need to at least specify all requirements with @param.
Descriptive and Helpful Messages
Exceptions are an essential tool for debugging, especially in logs. That’s why every exception deserves a meaningful, descriptive, and helpful message. There are 3 parts an exception can contribute:
- What happened? The exception type
- Where did it happen? The stack trace
- Why did it happen? The message
One of the best examples of why this is important is the NullPointerException.
It tells us what happened and where, but in the case of a fluent call, we might not exactly know which call or property caused it.
But we can tell who to blame in the message, and debugging just became easier.
Even Java itself realized that more information might be useful in the case of a NullPointerException.
With Java 14 the JVM option-XX:+ShowCodeDetailsInExceptionMessages was introduced (JEP 358):
// Fluent call that throws an exception
customer.getFirstname().toLowerCase();
// Before Java 14 or with the option disabled
Exception in thread "main" java.lang.NullPointerException
at ...
// Java 14+ with the option enabled
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.toLowerCase()" because the return value of "Customer.getFirstname()" is null
at ...As awesome as the additional information is, we have to consider the possible leakage of implementation internals to logs.
Nested try blocks
Even though nested try-blocks are possible, we should avoid them.
Besides from unnecessary complexity and less readability, any thrown exception in an inner block might be propagated to an outer try-block, if not handled, which could lead to subtle bugs.
Nested try-blocks should be refactored into multiple methods. This will make the code easier to reason with.
Don’t just Log & Rethrow
Never catch an exception just to log it, and throw it again:
try {
doWork();
}
catch (NullPointerException e) {
log.error("doWork() failed", e);
throw e;
}Either handle an exception or let it go up the call stack.
The upstream code has no way to know if an exception was already logged. And it might be propagated through multiple frames, should every single one log the exception?
If you can’t or won’t handle the exception, besides logging, let someone else handle it.
Some might argue that since throwing and catching exceptions are relatively costly operations, all this catching and rethrowing isn’t helping your runtime performance. Nor is it helping your code in terms of conciseness or maintainability.
An exception can be a chained exception, repackaging the information to be more specific and logging the original circumstances.
Don’t Swallow Exceptions
Exceptions fulfill a purpose, don’t just ignore them:
try {
doWork();
}
catch (Exception e) {
// NO-OP
}Like “Don’t just Log & Rethrow”, either handle an exception or let it propagate.
There are situations where we are not really interested in exception details and don’t want to propagate it further. Maybe we should at least log it, instead.
Too Many throws
Too many exceptions in the throws clause is an indicator of a method design weakness.
In an ideal world, methods would be small, self-contained, side-effect-free blocks of code.
If we need to add more and more exception types to throws, it’s a good sign the method is doing too much.
It’s better to have multiple methods, with a single throws, instead of an “everything” method, accumulating all exceptions.
Avoid Catching Exception or Throwable
Just like we should be specific when throwing exceptions, catching them comes down to the same thing. We shouldn’t catch Exception or Throwable directly. Use more specific types instead.
After catching more specific types, we might add an additional catch block with Exception to handle any additional cause.
But it’s a cheap “cop-out”, why not propagate it further, so someone might handle it appropriately?
throw & finally
The finally block is ensured to run after leaving a try block or its catch blocks.
What happens if we throw another exception in the finally block?
The finally block’s exception will cancel out any otherwise propagated exception:
try {
// might throw IllegalArgumentException
doWork();
// might throw ArithmeticException
doMoreWork();
}
catch (IllegalArgumentExcetion e) {
// handle exception
}
finally {
// might throw IOException
cleanup();
}The ArithmeticException is supposed to be propagated to the callee.
But if cleanup() throws an IOException, the original exception will be lost.
Another aspect to consider is the opposite: if we throw another exception in either the try or catch block, the finally block will still be executed:
try {
// might throw IOException
doWork();
doMoreWorkRequireingCleanup();
}
catch (IOException e) {
throw new RuntimeExcetpion(e)
}
finally {
// Will be called regardless of IOException
cleanup();
}Exceptions != Goto
Don’t confuse exceptions with an enterprisey-goto.
Exceptions are designed as disruptive events to the normal control flow, not as an addition to managing the ordinary control flow.
Especially business logic and stack trace-less exceptions should not be used to short-circuit the usual control flow. These invisible control flows make it hard to reason with our code, or even worse, with the code of other people.
A well-designed API must not force its clients to use exceptions for ordinary control flow.
— Effective Java by Joshua Bloch
As the name implies, they should be the exception, and not the new normal.
I’ve previously shown that in the non-exception case, it might be even faster than an additional if-check.
But if an exception occurs, the costs are significant.
Never replace a simple null-check with catching a NullPointerException.
Or checking array sizes by catching ArrayIndexOutOfBoundsException.
We should use the tools provided by the JVM, like exception handling, the way they were intended. Only this way can we be sure to get the best performance out of them.
Alternatives to (Checked) Exceptions
Exceptions are a great tool, but there are alternative ways to design our APIs without anticipated exceptions disrupting the normal control flow. It all depends on how strict your error-handling is supposed to be.
Imagine loading the content of a file:
interface FileLoader {
String loadContent() throws FileNotFoundException;
}How about returning an Optional<String>` instead of an exception?
interface FileLoader {
Optional<String> loadContent() throws IOException;
}If the Optional is empty, the file wasn’t found.
We still might need to handle other IOException, though.
The basic idea is handling any exceptional control flow in the implementation, instead of propagating an exception.
By choosing a more complex return value, we can communicate any problems back to the callee.
They might have to check the return value more thoroughly, but the scope of the exception changed.
In many cases, we might no longer need a throws anymore.
Other programming languages, even JVM-based ones like Scala, have specialized types for error handling, like Either[+A, +B], which can be either the one, or the other type.
Java doesn’t have such a flexible type.
The closest multi-state type is Optional.
Although it doesn’t convey any additional information.
But with its help we can build our own simplistic Either<L, R>:
import java.util.Optional;
import java.util.function.Consumer;
import java.util.function.Function;
public class Either<L, R> {
public static <L, R> Either<L, R> left(L value) {
return new Either<>(value, null);
}
public static <L, R> Either<L, R> right(R value) {
return new Either<>(null, value);
}
private final Optional<L> left;
private final Optional<R> right;
private Either(L left, R right) {
this.left = Optional.ofNullable(left);
this.right = Optional.ofNullable(right);
}
private Either(Optional<L> left, Optional<R> right) {
this.left = left;
this.right = right;
}
public <T> T map(Function<? super L, ? extends T> mapLeft, //
Function<? super R, ? extends T> mapRight) {
return this.left.<T> map(mapLeft) //
.orElseGet(() -> this.right.map(mapRight).get());
}
public <T> Either<T, R> mapLeft(Function<? super L, ? extends T> leftFn) {
return new Either<>(this.left.map(leftFn), //
this.right);
}
public <T> Either<L, T> mapRight(Function<? super R, ? extends T> rightFn) {
return new Either<>(this.left, //
this.right.map(rightFn));
}
public void apply(Consumer<? super L> leftFn, Consumer<? super R> rightFn) {
this.left.ifPresent(leftFn);
this.right.ifPresent(rightFn);
}
}Our code can now return an Either.left(errorInfo) or Either.right(successValue), and we can consume it in a functional fashion:
Either<Integer, String> result = doWork();
result.apply(errorCode -> log.error("Error {} occuring during work", errorCode),
value -> log.info("Success: {}", value));Conclusion
There’s more to Exceptions than at first glance. We have to know when and how to use them, and when not.
Exceptions aren’t free, but we can reduce their cost to a minimum. And if we must, we can even replace them with other constructs.
The one thing missing from this article is how to handle exceptions in Java Streams. It’s a topic in itself and deserves its own article.

Resources
- Java Tutorials on Exceptions (Oracle)
- Throwable Documentation (Oracle)
- Exception Handling in Java (Baeldung)
- Handling checked exceptions in Java streams (O’Reilly)
- Cost of Causing Exceptions (JavaSpecialist)
- The hidden performance costs of instantiating Throwables (Norman Maurer)
