The Bytecode Chicken-Egg Problem
Bytecode is the (mostly) invisible superpower of the Java Virtual Machine (JVM). Even though it’s an essential part of the Java ecosystem puzzle, it’s also a niche topic and behind-the-scenes feature that many of us do only have surface knowledge of. However, there’s a chicken-egg problem lurking within Bytecode libraries which the OpenJDK team intends to fix with JEP 484.
This is a quite long English write-up of my talk “The Bytecode Chicken-Egg Problem” I gave at JUG Karlsruhe in German. It a lot of things, including multiple code examples. Don’t worry too much about not understanding all of it; it’s the general idea of what the new Class-file API is trying to do that matters.
Table of Contents
The Bytecode Ecosystem
Programming languages usually fall into one of two categories: being interpreted by a runtime, like Python or JavaScript, or being compiled, like Go or Rust.
Both approaches have their advantages and caveats. Interpreted languages run code anywhere their runtime is available. Compiled languages, on the other hand, must be, well, compiled to work on a specific platform, and the result only works on them.
Java, however, can be seen as a hybrid, thanks to the way the JVM works. On the surface, the JVM interprets Bytecode, a platform-agnostic intermediate code representation which is created by the platform-specific Java compilers.

This way, our Java code is compiled once and runs on any platform having a JVM to run it. And the best part is that the JVM is compiling it further to optimize it based on usage, but more about that later.
Here’s an example of a simple “hello world” in Java:
public class HelloBytecode {
public static void main(String... args) {
System.out.println("Hello, Bytecode!");
}
}And this is how the JVM sees the Bytecode which it will interpret:
Compiled from "HelloBytecode.java"
public class HelloBytecode {
public HelloBytecode();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String...);
Code:
0: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #13 // String Hello, Bytecode!
5: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
}Not many of us are working directly with Bytecode or write it “by hand” in our day-to-day jobs. But it’s an essential part of many of the frameworks and libraries we use daily. That’s why I strongly believe a deeper knowledge is beneficial for any Java developer.
Bytecode Use-Cases
The most obvious use-cases for Bytecode are compiler backends.
Languages like Kotlin, Scala, Groovy, Clojure, etc., all compile down to Bytecode to integrate nicely in the overall Java ecosystem. But there are also languages we’re not usually associating with Java, like JRuby or Jython, that run on the JVM by leveraging Bytecode.
That’s how the JVM runs so many programming languages, because it actually only runs a single one: Bytecode. Running only one language makes all the original ones cross-compatible, so it doesn’t matter which language a dependency was written in, as long as it’s JVM compatible.
The next use-case for Bytecode is implementing specific language features.
Many of our favorites, like Lambdas/Functional Interfaces, or the dynamic nature of Groovy, heavily rely on particular Bytecode instructions like invokedynamic and wouldn’t be possible, or at least as efficient, without it.
Bytecode is generated and used during both compile-time and runtime. For example, the Micronaut framework is providing dependency injection at compile-time by working directly with Bytecode.
At runtime, a lot of frameworks, like Spring, Apache Tapestry, Hibernate or Mockito, facilitate Bytecode generation for a myriad of functionality: dependency injection, entity enhancements, dynamic proxies, mocking, and much more.
Lots of tooling uses Bytecode for many reasons, like PMD for static code analyzing, or IDEs for getting a better understanding or disassembling class files.
Whenever there are cross-cutting concerns, like logging, enforcing security policies, etc., Bytecode manipulation can be a practical approach to integrate functionality even without access to the actual source code.
Now that we looked at what Bytecode is used for, it’s time to check out how to work with it.
Working with Bytecode
There’s a spectrum of Bytecode manipulation libraries available, ranging from low-level libraries where you write the instructions almost by hand, and high-level libraries abstracting away many of the complexities and providing a more Java-like experience.
At the lower end is the wide-spread and well-known library ASM. It’s an “all-purpose” Bytecode manipulation and analysis library that’s quite close to the metal, and you better have a good understanding of Bytecode when you want to use it. The user guide being a whopping 154 pages long PDF is a good indication that there’s quite some complexity to it.
At a higher level, there’s Javassist. Besides a Bytecode-oriented API, it provides a source code approach, too, that doesn’t require any knowledge of Bytecode.
ByteBuddy is even more high-level, but aims at runtime generation. Its fluent API is easy to use, yet powerful.
There are more libraries available, but I tried to restrict the list to the most prominent/known ones.
The Bytecode Chicken-Egg Problem
In the previous section, we learned about Bytecode in general, how it’s used and the available ecosystem of Bytecode manipulation libraries. So, the immediate question we have to ask… why do we need another one?
Well, it’s the reason for this article and the title of my talk: The Bytecode Chicken-Egg-Problem.
Instead of going right into it, we look at the underlying circumstances that led to the problem in the first place.
Fast-Paced Java Evolution
For quite a long time of its existence, Java wasn’t known for fast-paced improvements or frequent releases.
Java 6 to 7 took 4 years and 7 months.
Java 7 to 8 took another 2 years and 9 months.
And 8 to 9 required a wait of 3 years and 6 months.
These are quite long periods without any major changes or new features.
Finally, with Java 9, everything changed, when the OpenJDK team switched their approach to releases and established a fixed timeframe release cadence: 6 months.
Instead of waiting possibly years for new features and major changes, whether at the library, language, or Bytecode level, we now get a new Java version every 6 months!
This is achieved by allowing features to be released as soon as they’re “done”, and not waiting for a specific releases. On average, each release contains around 12 JEPs, including many preview or incubator features, to gather feedback early and shape features with the help of the community.
On the one hand, it’s awesome to no longer have to wait years for new features, especially since there’s a lot of interesting things on the horizon that will affect the language for years to come. But that also means that libraries and frameworks have to deal with a new Class-file version every 6 months and need to be updated.
To make it even worse, the JDK itself needs to adapt, too, as it uses ASM (and at least two more libraries) for some of its Bytecode needs!
And that’s the source of the chicken-egg problem.
The JDK’s Chicken-Egg Problem
It’s actually quite simple.
When a new Java version is released, the Class-file version is increased.
Therefore, a newer ASM version is required for the JDK to actually generate that Bytecode.
For the JDK to update ASM, it needs to be finalized.
The problem, though, for ASM to be finalized, it needs a released JDK version.
To “solve” this, a new JDK version can only bundle the ASM version targeting its predecessor.

That interdependency delays any features requiring newer Bytecode, until the next JDK release.
One could argue about why they don’t work closely with ASM, or work with preview versions. But I’m sure they already do that to make sure anything works fine.
However, releasing an official Java version build against preview libraries is another thing. So I totally get it why they’re doing it the way they’re doing it.
More Chicken-Egg Problems
The JDK isn’t alone in having this particular problem, though. Frameworks and libraries are in a similar predicament, just a little further along the chain.
Many frameworks shade or vendor a specific Bytecode manipulation library to make sure that the correct version of it is used for their Bytecode needs. Sometimes, they even have project-specific changes, like we have in Apache Tapestry. It’ a single-line change, but it still makes every update more complex.
The JDK solves the issue by delaying features, but what happens if a framework or library doesn’t support a newer version?
Dependency Road Blocks
Imagine a typical Java application with 4 primary dependencies.
Transitive dependencies make it a little more complicated.
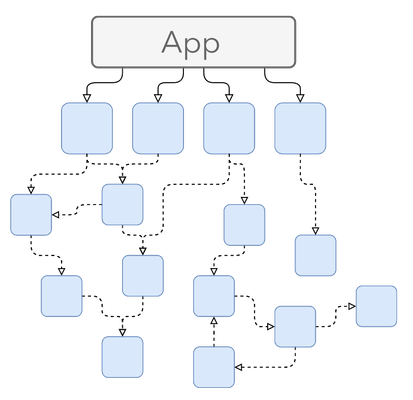
Not quite the dependency-hell like in other languages (*cough* JavaScript *cough*), but still not straightforward in many cases.
If a new Java version is released, and all the dependencies get updated, except one, this problem travels upwards and prevents us from updating the app as a whole.
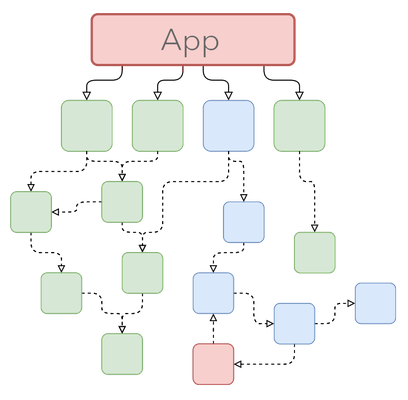
So, what can we do to mitigate?
How to Deal with the Chicken-Egg Problem
The best place to deal with the problem is at the Class-file library level, as they are closest to the new Class-file version.
What are our options, then?
Fail Hard
Well, that’s what’s happening right now.
Class-file versions have guaranteed backward compatibility but not forward compatibility.
Even if we’re not using any new Bytecode features, and it might work, risking any problems isn’t worth it, so failing hard is the only way to go.
YOLO
Forward compatibility might not be guaranteed, but what about trying anyway? ¯\_(ツ)_/¯
We could to read any Class-file, ignore parts we don’t understand, work with pre-release versions, etc.
For production code, that’s no reliable and even straight-up dangerous approach, and I wouldn’t recommend it in any way.
A New Class-File API
How about a Class-file API directly in the JDK, which is always up-to-date and supports all Bytecode features as soon as they’re available?
Let’s take a look!
Towards a new Class-File API
First, we take a step back.
There’s already an extensive ecosystem of mature solutions available, so why not work closer with one of them or even integrate them, similar to Joda-Time became the foundation of Java’s Date and Time API?
Many of the available libraries are quite specific solutions. Like most code, they emerged to solve a particular problem, and weren’t “designed” to be a general API for Bytecode needs. That confines them into a certain way of thinking and kind of restricts their evolutionary path.
Don’t get me wrong, I don’t mean to talk bad about these libraries! Having a particular design philosophy and opinionated way toward the future is essential. But we’re talking about comparing it to a possible green-field project.
The main reason for creating a new API was the possibility of designing it and explicitly co-evolving along the specifications. And, of course, hubris, because they can… Brian Goetz said it, not me ;-)
How to Design a Class-File API
After the decision to do it, the next question anyone designing a new API should ask is how?
One approach would be assimilating the status quo, similar to how JSR 310 has its root in Joda-Time. This way, developers don’t need to learn an entirely new API and approach things differently.
So, which library could be assimilated, as the JDK is using at least three of them?
ASM seems like the best candidate, as it’s wide-spread, low-level for all kinds of tasks.
A Closer Look At ASM
ASM is a powerful Bytecode manipulation library that was first released in 2002.
It’s one of the best in its class, but as with all code, design choices lead to compromises, especially when some of these choices stem back over 20 years.
One major design choice of ASM is “performance over ergonomics”. That’s understandable, as the raw performance we enjoy today wasn’t always ubiquitous.
However, we do not only have more power at our fingertips, but Java itself is not the same language anymore. Many new features aim at developer experience and ergonomics first, instead of making raw performance the top priority.
Another aspect that feels dated is ASM’s general approach, the visitor pattern.
Example: Simple Method with ASM
Let’s write a method with ASM, so we have a baseline example to compare the new API with.
Image this simplistic method:
void fooBar(boolean cond, int val) {
if (cond) {
foo(val);
}
else {
bar(val);
}
}How would something this simple be created with ASM?
// CREATE ClassWriter, VISIT METHOD NAD VISIT CODE TO START
ClassWriter classWriter = ...;
MethodVisitor mv = classWriter.visitMethod(0, "fooBar", "(ZI)V", null, null);
mv.visitCode();
// LOAD LOCAL VARIABLE IDX 1
mv.visitVarInsn(ILOAD, 1);
// CREATE LABEL FOR ELSE
Label labelElse = new Label();
// COMPARE STACK AND JUMP TO ELSE
mv.visitJumpInsn(IFEQ, labelElse);
// LOAD this
mv.visitVarInsn(ALOAD, 0);
// LOAD LOCAL VARIABLE IDX 2
mv.visitVarInsn(ILOAD, 2);
// CALL Foo.foo(int)
mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "foo", "(I)V", false);
// CREATE LABEL FOR RETURN
Label labelReturn = new Label();
// CONDITIONLESS JUMP
mv.visitJumpInsn(GOTO, labelReturn);
// START LABEL ELSE
mv.visitLabel(labelElse);
// LOAD this
mv.visitVarInsn(ALOAD, 0);
// LOAD LOCAL VARIABLE IDX 2
mv.visitVarInsn(ILOAD, 2);
// CALL Foo.bar(int)
mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "bar", "(I)V", false);
// START LABEL RETURN
mv.visitLabel(labelReturn);
// RETURN
mv.visitInsn(RETURN);
// FINISH METHOD IMPLEMENTATION
mv.visitEnd();Well, that’s a lot of code for a simple if-else…
What does (ZI)V mean?
It’s the Bytecode way of saying “accepts a boolean (Z) and a int (I) and returns void (V)”
Why is the IFEQ jumping to labelElse?
Because it compares the top-most stack variable against 0 (zero).
As you can see, there’s definitely detailed Bytecode knowledge required to understand even such a simple example.
It perfectly illustrates the complexity and boilerplate needed to do even simple tasks. Paired with the visitor pattern, it creates a complicated API, that might be powerful, but not much fun to use.
Looking deeper than just the code, the visitor pattern and its explicit traversal also creates a rigid structure with explicit traversal and even has performance implications.
So, it’s time for something better!
Design Goals
We can design a better API because we have a better language now
– Brian Goetz, JVM Language Summit 2023
The design goals of the new API are simple:
Ergonomics over Performance
Developer experience is more important than ever. If you want to encourage devs to actually use your API, it must be easy to learn, expressive, flexible, safe, …“Good” Performance
That doesn’t mean performance isn’t important. But it shouldn’t be allowed to dictate every design choice.Solid & Modern Foundation
Lambdas, Records, Sealed Classes, Pattern Matching… All the bells and whistles available in Modern Java.Model-Driven Design
The design should be based around the Class-file model itself and present a unified view towards any workflow.
The most important point here is the “Model-Driven Design”, as it builds the foundation the whole API will stand on.
One Data Model To Rule Them All
Class-files are well-specificed, strongly typed trees. They’re containers holding the Bytecode and associated Metadata, so the JVM can execute the file.
The format is explicitly designed to be modular and extensible without breaking or changing the core structure. That’s why it’s an excellent basis for the data model. And not just any model, a creative one.
A creative model means it’s doing the heavy lifting by representing every aspect of the Class-files. With such a model, the API is merely derived from it. Any complexity needs to be handled by the model, not the API.
Basic API Concept
The basic concept of the Class-file API is build around 3 parts:
- Models
- (Compound) Elements
- Builders
Each part of a Class-file is represented by a model, which describe elements. Complex elements are compounded, meaning they consist of multiple elements.
Going from models to elements is the aspect of “reading” in the API. It can be done sequentially, but random-access to elements is also possible.
Elements can be created and manipulated, representing the “transformation” aspect of the API.
And finally, builders, which accept elements, transformed or not. This is how Bytecode is “written” by the API.

By simplifying the workflows to these three steps, a uniform API emerged using the same idioms regardless of what you want to do with any of the involved moving parts. That makes it easier to learn, expressive and straightforward to use.
From Data Model to API
The models and elements are defined in a quite expansive hierarchy of sealed types.
For example, the top-most model, ClassModel, gives sequential and random access, among other things:
sealed interface ClassModel
extends CompoundElement<ClassElement>, AttributedElement {
Iterator<ClassElement> iterator();
List<ClassEntry> interfaces();
List<MethodModel> methods();
// ...
}ClassElement represents each element of a Class and permits 31 types:
sealed interface ClassElement extends ClassfileElement
permits AccessFlags, Superclass, Interfaces, ClassFileVersion,
FieldModel, MethodModel, CustomAttribute, ... { /* ... */ }ClassFileElement represents more details:
sealed interface ClassFileElement
permits AttributedElement, CompoundElement, Attribute,
ClassElement, CodeElement, FieldElement, MethodElement { /* ... */ }And CompoundElement lets us work with the element directly or as Iterable<E>:
sealed interface CompoundElement<E extends ClassfileElement>
extends ClassfileElement, Iterable<E>
permits ClassModel, CodeModel, MethodModel, FieldModel { /* ... */ }The overall type hierarchy seems quite complicated when looked at in isolation But that’s exactly the complexity/creativity I was talking about previously. Using them is way more intuitive than it seems right now.
Why Builders?
The API facilitates Builders, as they simplify object creation and are more flexible and extendable than the visitor pattern.
However, as the API also uses all the bells and whistles available, there’s a certain twist, which I call the “Builder-Builder Pattern”.
Instead of creating a Builder and calling the factory methods directly, the API accepts Consumers of these Builders:
sealed interface ClassFileBuilder<E extends ClassFileElement, B extends ClassFileBuilder<E, B>>
extends Consumer<E>
permits ClassBuilder, FieldBuilder, MethodBuilder, CodeBuilder { /* ... */ }The ClassFileBuilder, the starting point, is a Consumer<E extends ClassFileElement>.
To work with other elements, we call the appropriate method that accepts another Consumer for a corresponding builder, like seen here for ClassBuilder:
sealed interface ClassBuilder
extends ClassFileBuilder<ClassElement, ClassBuilder>
permits ChainedClassBuilder, DirectClassBuilder {
ClassBuilder withMethod(Utf8Entry name,
Utf8Entry descriptor,
int methodFlags,
Consumer<? super MethodBuilder> handler);
ClassBuilder withField(Utf8Entry name,
Utf8Entry descriptor,
Consumer<? super FieldBuilder> handler);
// ...
}This approach is found in the whole API, making all the tasks follow the same idioms.
Using Consumer instances instead of writing the code directly also decouples the code, making the lambdas composable and reusable, and allowing for a lot of optimization techniques behind-the-scenes.
Enough about theory and interface declarations, let’s talk code!
Working with Bytecode
The previous ASM example is a good starting point to see how we’d approach the same problem with the new Class-file API:
ClassWriter classWriter = ...;
MethodVisitor mv = classWriter.visitMethod(0, "fooBar", "(ZI)V", null, null);
mv.visitCode();
mv.visitVarInsn(ILOAD, 1);
Label labelElse = new Label();
mv.visitJumpInsn(IFEQ, labelElse);
mv.visitVarInsn(ALOAD, 0);
mv.visitVarInsn(ILOAD, 2);
mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "foo", "(I)V", false);
Label labelReturn = new Label();
mv.visitJumpInsn(GOTO, labelReturn);
mv.visitLabel(labelElse);
mv.visitVarInsn(ALOAD, 0);
mv.visitVarInsn(ILOAD, 2);
mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "bar", "(I)V", false);
mv.visitLabel(labelReturn);
mv.visitInsn(RETURN);
mv.visitEnd();Using the Builder-Builder Pattern
Transforming the ASM example to the new API follows the same general structure, as we still need the same Bytecode instructions. But instead of using the visitor pattern, the code is utilizing Lambdas and Builders:
// CREATE ClassBuilder AS STARTING POINT WHICH ACCEPTS A MethodBuilder,
// WHICH ACCEPTS A CodeBuilder
ClassBuilder classBuilder = ...;
classBuilder.withMethod("fooBar", MethodTypeDesc.of(CD_void, CD_boolean, CD_int), flags,
(MethodBuilder methodBuilder) -> methodBuilder.withCode((CodeBuilder codeBuilder) -> {
// CREATE LABELS
Label labelElse = codeBuilder.newLabel();
Label labelReturn = codeBuilder.newLabel();
// FLUENT BUILDER CALLS
codeBuilder.iload(1)
// COMPARE STACK AND JUMP TO labelElse IF NECESSARY
.ifeq(labelElse)
// BRANCH if
.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "foo",
MethodTypeDesc.of(CD_void, CD_int))
.goto_(labelReturn)
// BRANCH else
.labelBinding(labelElse)
.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "bar",
MethodTypeDesc.of(CD_void, CD_int))
// RETURN
.labelBinding(labelReturn)
.return_();
}));The first thing you notice is the nested structure thanks to the Lambdas.
The labels are created beforehand, and one fluent call on a CodeBuilder implements the method instead of multiple visit... method calls (they all return void).
The implementation itself is almost identical, with factory methods named after the Bytecode instructions. But one thing is jumping right at us: less stringly-typed code.
Previously, the method signature was defined as (ZI)V for the method signature.
Now, it’s a more straightforward and strongly-type MethodTypeDesc.of(CD_void, CD_boolean, CD_int).
What’s going on?
The java.lang.constant Package
To make the API safer and more expressive, the package java.lang.constant contains nominal descriptors for Classes, Methods Types, and more.
This makes using the new API more strongly-typed than stringly-typed.
We can create our own ClassDesc, MethodTypeDesc, MethodHandleDesc, and more, or use one of 46 predefined ClassDesc instances available as static fields on ConstantDescs.
There’s also constants like NULL, TRUE, and FALSE available.
Even More Lambdas
Even though we’ve already seen quite an improvement over ASM and the visitor pattern, there’s still a lot to be desired for a modern and ergonomic API.
For one thing, it feels quite “Bytecodey” and not like a Java developer would approach problems, like the ifeq that jumps over the if-branch instructions.
So, how about introducing more lambdas?
ClassBuilder classBuilder = ...;
classBuilder.withMethod("fooBar", MethodTypeDesc.of(CD_void, CD_boolean, CD_int), flags,
(MethodBuilder methodBuilder) -> methodBuilder.withCode((CodeBuilder codeBuilder) -> {
codeBuilder.iload(1)
.ifThenElse(
bIf -> bIf.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "foo",
MethodTypeDesc.of(CD_void, CD_int)),
bElse -> bElse.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "bar",
MethodTypeDesc.of(CD_void, CD_int))
.return_();
});The CodeBuilder does not only have instruction methods, but many convenience methods like ifThenElse, too!
And if you think about, it makes a lot of sense.
The boilerplate required to realize a if-else in Bytecode is constant: a Label for else, call ifeq and jump to label, add if instructions, create else label and instructions.
That’s way it’s so easy to abstract away and do it behind-the-scenes.
It feels a little like external versus internal iteration, so like a for-loop versus a Stream.
Do we need to know what’s actually happening in the boilerplate?
Not really (most of the time).
So instead, let’s concentrate on what’s important: the actual implementation in the form of 2 Consumer arguments on ifThenElese.
The code becomes cleaner and way more straightforward, as the method replaces obvious boilerplate with a simpler call. Also, using lambdas for the branches decouples them once again from the builder, making them reusable, composable, and all the other advantages that automagically come with Lambdas.
Most of the boilerplate and fragility were already replaced by more modern alternatives, but one mystery thingie remains: parameter indices.
Variable Management
Local parameters are accessed via an indexed value store, with 0 being the this, and 1 being the first parameter, and so forth.
However, the slots storing the parameters have a fixed size of 32 bits, but not everything in Java is only 32 bit…
long and double are 64 bit, so they span 2 slots, making the index needed to a specific parameter depend on the actual method signature/stored parameters.
How about asking someone who actually knows the method signature and, therefore, the correct index, like CodeBuilder?
The CodeBuilder knows about the method signature thanks to the constant API, so it knows how to get the parameters based on their index in the signature, not their actual type.
The previous 0 (zero) index gets detached from the other parameters into receiverSlot, and all the parameter slots start now at 0 (zero):
ClassBuilder classBuilder = ...;
classBuilder.withMethod("fooBar", MethodTypeDesc.of(CD_void, CD_boolean, CD_int), flags,
(MethodBuilder methodBuilder) -> methodBuilder.withCode((CodeBuilder codeBuilder) -> {
// 1 -> 0
codeBuilder.iload(codeBuilder.parameterSlot(0))
.ifThenElse(
// 0 -> receiverSlot
bIf -> bIf.aload(codeBuilder.receiverSlot())
// 2 -> 1
.iload(codeBuilder.parameterSlot(1))
.invokevirtual(ClassDesc.of("Foo"), "foo",
MethodTypeDesc.of(CD_void, CD_int)),
// 0 -> receiverSlot
bElse -> bElse.aload(codeBuilder.receiverSlot())
// 2 -> 1
.iload(codeBuilder.parameterSlot(1))
.invokevirtual(ClassDesc.of("Foo"), "bar",
MethodTypeDesc.of(CD_void, CD_int))
.return_();
});So far, we replaced almost all non-strong-typed things and magic numbers, and replaced unnecessary boilerplate with a convenience method.
The only ambiguous things remaining is the String in ClassDesc.of("Foo"), which we could easily refactor and reuse.
That only leaves the method names "foo" and "bar".
Quite an improvement over the ASM example, don’t you think?
Builder-Builders & Constant API
In my opinion, the Builder-Builder approach paired with the strong-type constant API creates an excellent developer experience and overall ergonomics. We still need to know Bytecode details, but the level shifted a little upwards from the lowest level.
Constants and fewer magic numbers make the code safer and less error-prone, and factory methods like ifThenElse make the code expressive and more straightforward.
And the best part is that it’s still “mostly” efficient. It’s fast enough in most cases, by being “on-demand” and doing only what’s necessary. Reusing descriptors and lambdas also helps a lot. But I’ll get into that a littler later.
Transforming Classes
Transforming elements is simple: Reading a Class-file, navigate to the desired element, modify it, and push it into the builder.
Let’s write the necessary code to drop all methods that start with debug:
// READING A CLASS-FILE
Classfile cf = Classfile.of();
ClassModel classModel = cf.parse(path) ;
byte[] bytes =
cf.build(classModel.thisClass().asSymbol(),
(ClassBuilder classBuilder) -> {
// ACCESS ELEMENT SEQUENTIALLY VIA MODEL
for (ClassElement classElement : classModel) {
// IDENTIFY ELEMENTS VIA PATTERN MATCHING AND MORE
if (classElement instanceof MethodModel mm
&& mm.methodName().stringValue().startsWith("debug")) {
// NO-OP
continue;
}
// OTHER ELEMENTS FLOW BACK INTO THE classBuilder
classBuilder.with(classElement);
}
});Any element not making it back into the classBuilder is dropped.
Overall, this seems like a straightforward approach. But there’s a problem… what if we have a more complex logic required to find the correct element and want to do more than just “nothing”?
Classfile cf = Classfile.of();
ClassModel classModel = cf.parse(path) ;
byte[] bytes =
cf.build(classModel.thisClass().asSymbol(),
classBuilder -> {
for (ClassElement classElement : classModel) {
if (classElement instanceof MethodModel mm) {
classBuilder.withMethod(mm.methodName(), mm.methodType(),
mm.flags().flagsMask(), methodBuilder -> {
for (MethodElement me : mm) {
if (me instanceof CodeModel codeModel) {
methodBuilder.withCode(codeBuilder -> {
for (CodeElement e : codeModel) {
switch (e) {
case InvokeInstruction i when i.owner().asInternalName().equals("Foo")) ->
codeBuilder.invokeInstruction(i.opcode(), ClassDesc.of("Bar"),
i.name(), i.type());
default -> codeBuilder.with(e);
}
}
});
}
else {
methodBuilder.with(me);
}
}
});
}
else {
classBuilder.with(ce);
}
}
});What a mess…
Lots of repetitive boilerplate, quite a lot exploding elements and navigation necessary.
How about we concentrate on what we actually want to do, the transformations, and not the boilerplate surrounding them?
Removing debug again
We look at the first transformation example, as it’s shorter and easier to grasp.
The actual transformation inside the ClassBuilder was:
for (ClassElement classElement : classModel) {
if (classElement instanceof MethodModel mm
&& mm.methodName().stringValue().startsWith("debug")) {
continue;
}
classBuilder.with(classElement);
}What we’re doing is here performing a transformation on each element.
The actual logic can be represented by one of the new ...Transform types, which has access to the corresponding ...Builder and ...Element:
ClassTransform classTransform = (classBuilder, classElement) -> {
if (classElement instanceof MethodModel mm
&& mm.methodName().stringValue().startsWith("debug")) {
return;
}
classBuilder.with(classElement);
};To run this ClassTransform, we need to call tranform(...) instead of build(...):
Classfile cf = Classfile.of();
ClassModel classModel = cf.parse(path);
byte[] bytes = cf.transform(cm, classTransform);What happens here is that the ClassTransform is applied to all ClassElement objects in the ClassFile.
The looping is done by the transform(...) call.
In the case of dropping an element, there’s even a convenience method available, similar to the Stream APIs Collectors class:
ClassTransform classTransform =
ClassTransform.dropping(
classElement -> classElement instanceof MethodModel mm
&& mm.methodName().stringValue().startsWith("debug"));Once again, the API takes care of repetitive boilerplate, and we can concentrate on the important things.
Working at the Correct Level
As mentioned before, there’s more than ClassTransform, but the transform(...) method only accepts those.
If we want to work with, for example, a CodeTransform, we need to lift the transformation to Class-level.
Let’s create a CodeTransform that redirects invokestatic calls from Foo to another type called Bar:
CodeTransform redirectFooBar = (codeBuilder, codeElement) -> {
// IDENTIFY CORRECT ELEMENT/INSTRUCTION
if (codeElement instanceof InvokeInstruction i
&& i.opcode() == Opcode.INVOKESTATIC
&& i.owner().asInternalName().equals("Foo")) {
// CREATE NEW INSTRUCTION ON codeBuilder
codeBuilder.invoke(Opcode.INVOKESTATIC,
ClassDesc.of("Bar"),
i.name().stringValue(),
i.typeSymbol(),
i.isInterface());
return;
}
// PASSTHROUGH OTHER ELEMENTS
codeBuilder.with(codeElement);
};Another simple transformation decoupled from actual code, so it’s easy to reuse.
But if we want to transform a ClassFile, we need to lift it to a MethodTransform first, and then, a ClassTransform:
// CREATE TRANSFROM
CodeTransform redirectFooBar = ...;
// LIFT TRANSFORM
MethodTransform methodTransform = MethodTransform.transformingCode(redirectFooBar);
ClassTransform classTransform = ClassTransform.transformingMethods(methodTransform);
// TRANSFORM Classfile
Classfile cf = Classfile.of();
ClassModel classModel = cf.parse(path);
byte[] bytes = cf.transform(classModel, classTransform);It might seem a little weird at first, but having different levels to work on gives the transformations a particular confinement to work within, and create more concise and on-point transformations. Lifting them allows us to compose them to more complex transformations.
Composing Transformations
Let’s create another CodeTransform to log any method call:
CodeTransform logMethodCall = (codeBuilder, codeElement) -> {
// IDENTIFY METHOD INVOKES
if (codeElement instanceof InvokeInstruction i) {
// ADD CALL System.out.println
codeBuilder.getstatic(CD_System, "out", CD_PrintStream)
.ldc(i.name().stringValue())
.invokevirtual(CD_PrintStream, "println", MTD_void_String);
}
// PASS ORGINAL ELEMENT
codeBuilder.with(codeElement);
};Same approach as before, nothing unexpected.
But now, we can combine both redirectFooBar and logMethodCall:
// CREATE TRANSFORMS
CodeTransform redirectFooBar = ...;
CodeTransform logMethodCall = ...;
// COMPOSE
CodeTransform composedTransform = redirectFooBar.andThen(logMethodCall);
// LIFT
ClassTransform transform =
ClassTranform.transformingMethods(
MethodTransform.transformingCode(composedTransform)
);
// TRANSFORM Classfile
Classfile cf = Classfile.of();
ClassModel classModel = cf.parse(path);
byte[] bytes = cf.transform(cm, transform);Combining/composing Transformations reminds me a lot of how the Stream API gives us the possibility to create stateless op and mix and match as needed.
Transformations give us isolated, (mostly) pure functions to build up a library of commonly used stuff, or use such libraries from the ecosystem in the future. Working on the correct level allows the JDK to optimize the hell out of it. And there’s still the possibility to do inline transformation instead, we’re not restricted to the Transformation API.
Mission Accomplished?
That was quite a lot of information… time to revisit the design goals and check if the new API fits the bill.
Design Goals Revisited
First and foremost, ergonomics should have priority over performance. That’s a yes.
The API surface is quite ergonomic and gives us an expressive and safe way to interact with it thanks to the Builder-Builder pattern, the constant API and more.
This also leads into the next point, that the API should be easy to learn, etc.
Being unified with the same idioms wherever you are is great.
Convenience methods like ifThenElse make it even easier for us.
How about a solid and modern foundation? Hell yes!
The OpenJDK team pulled out all the stops and leveraged every available Java features to create a fresh and modern API. Records, sealed types, pattern matching, lambdas, functional approaches… awesome!
It’s all built around the model-driven design, which, I admit, can be quite confusing at first, but makes a lot of sense when you get to know it a little.
What about Performance?
One topic I didn’t talk much about is the overall performance. Even though it’s not a top-priority, it’s still a necessity, especially if it’s used in the compiler. And things like Immutability induces a performance head and might lead to unnecessary object creation on changes, etc.
Of course, the OpenJDK didn’t design such a great API and then realized that there’s a performance issue. Everything the API does is optimized on different levels.
The simplest optimization is doing as little as possible, making most representations on-demand and parse only what’s actually needed. Laziness is the general approach to everything.
Another optimization compared to other libraries like ASM is bulk-copying unchanged things like constant pools or stack maps instead of rebuilding them.
The optimizations are even at a level like preventing String creation.
Maybe you noticed in one of the examples that there always was an additional call between names and String operations, like: mm.methodName().stringValue().startsWith("debug").
That’s because names are represented by Utf8Entry instances, so no String is created unless it’s actually needed.
This accumulates to a performant API, that’s faster in some aspects, but slower in others. You “pay” for what you use, which means you can get away cheaper than compared to an “all-you-can-eat buffet”.
Chicken-Egg Problem Solved?
I’d say yes, but…
The JDK solved the problem for itself. No more waiting for third-party libraries to generate up-to-date Bytecode, meaning we don’t have to wait for features.
The bigger picture, though, is more complicated. Framework and libraries can use the new API, too, to mitigate the overall issue, but the timeframe is quite different. The JDK profits from the new API as soon as its released, but until we, as developers, can use it in our favorites dependencies might take months or even years!
Every project invested quite a lot of work in their Bytecode manipulation code and can’t replace it with the new API, even if it has many advantages. But hopefully, over time, more and more frameworks will switch over to make updates to newer Java version more straightforward.
One thing the OpenJDK team emphasizes is that the API is not supposed to replace all the others, as there’s no one-size-fits-all solution. There’s a reason we have so many Bytecode manipulation libraries at different levels.
As I see it, the new API could have easily created for internal-use only. But instead, the OpenJDK team created a modern and fresh API showcasing all the modern features available. It solves not just a singular pain point they had, but looking at the overall picture and creating a wholesome solution for the subject. We directly benefit from it by no more delayed features, but for the overall ecosystem, they’re playing the long game.
But in my opinion, it’s worth the wait, and I’m looking forward to the release of the new API!

Resources
JEPs
Videos
- JVMLS 2023: A Classfile API for the JDK (Brian Goetz)
- New Class-File API will make Java Updates easier - Inside Java Newscast #56 (Nicolai Parlog)
